Pattern Matching
Strings
- A string is a sequence of characters
- Examples of strings: Java program, HTML document, DNA sequence, Digitized image
- An alphabet Σ is the set of possible characters for a family of strings
- Example of alphabets: ASCII, Unicode, {0, 1}, {A, C, G, T}
- Let P be a string of size m
- A substring P[i .. j] of P is the subsequence of P consisting of the characters with ranks between i and j
- A prefix of P is a substring of the type P[0 .. i]
- A suffix of P is a substring of the type P[i ..m − 1]
- Given strings T (text) and P (pattern), the pattern matching problem consists of finding a substring of T equal to P
- Applications: Text editors, Search engines, Biological research
Brute-Force Algorithm
- The brute-force pattern matching algorithm compares the pattern P with the text T for each possible shift of P relative to T, until either
- a match is found,
- or all placements of the pattern have been tried
- Brute-force pattern matching runs in time O(nm)
- Example of worst case:
- T = aaa … ah
- P = aaah
- may occur in images and DNA sequences
- unlikely in English text
Algorithm BruteForceMatch(T, P)
Input text T of size n and pattern P of size m
Output starting index of a substring of T equal to P or −1 if no such substring exists
for i ← 0 to n − m
{ test shift i of the pattern }
j ← 0
while j < m ∧ T[i + j] = P[j]
j ← j + 1
if j = m
return i {match at i}
else
break while loop {mismatch}
return -1 {no match anywhere}
Boyer-Moore Heuristics
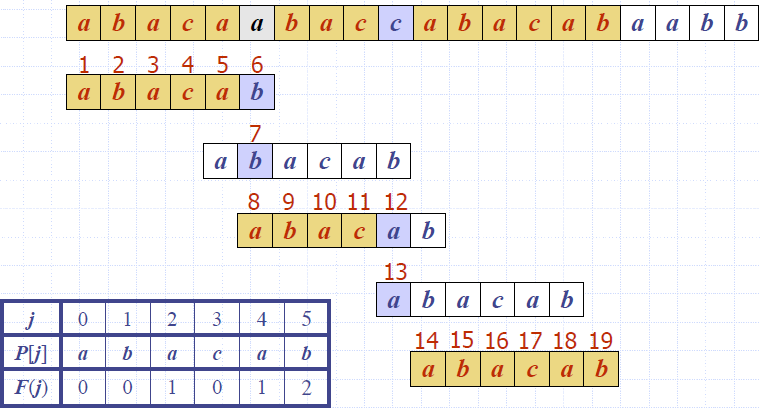
- The Boyer-Moore’s pattern matching algorithm is based on two heuristics
- Looking-glass heuristic: Compare P with a subsequence of T moving backwards
- Character-jump heuristic: When a mismatch occurs at T[i] = c
- If P contains c, shift P to align the last occurrence of c in P with T[i]
- Else, shift P to align P[0] with T[i + 1]
- Example
Last-Occurrence Function
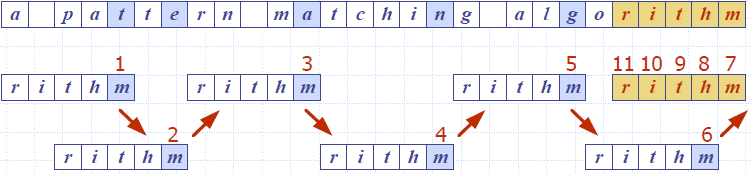
- Boyer-Moore’s algorithm preprocesses the pattern P and the alphabet Σ to build the last-occurrence function L mapping Σ to integers, where L(c) is defined as
- the largest index i such that P[i] = c or
- −1 if no such index exists
- Example:
- Σ = {a, b, c, d}
- P = abacab

- The last-occurrence function can be represented by an array indexed by the numeric codes of the characters
- The last-occurrence function can be computed in time O(m + s), where m is the size of P and s is the size of Σ
The Boyer-Moore Algorithm
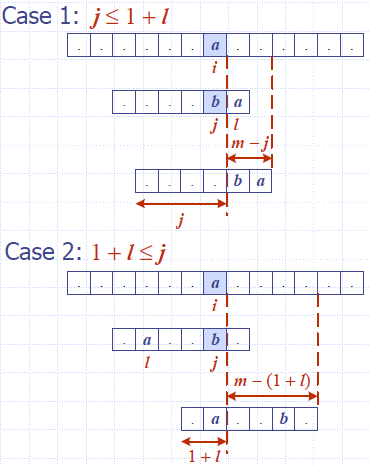
Algorithm BoyerMooreMatch(T, P, Σ)
L ← lastOccurenceFunction(P, Σ )
i ← m − 1
j ← m − 1
repeat
if T[i] = P[j]
if j = 0
return i { match at i }
else
i ← i − 1
j ← j − 1
else
{ character-jump }
l ← L[T[i]]
i ← i + m – min(j, 1 + l)
j ← m − 1
until i > n − 1
return −1 { no match }
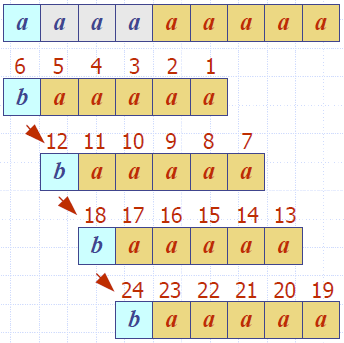
Analysis
- Boyer-Moore’s algorithm runs in time O(nm + s)
- Example of worst case:
- The worst case may occur in images and DNA sequences but is unlikely in English text
- Boyer-Moore’s algorithm is significantly faster than the brute-force algorithm on English text
Knuth-Morris-Pratt’s algorithm
- Knuth-Morris-Pratt’s algorithm compares the pattern to the text in left-to-right, but shifts the pattern more intelligently than the brute-force algorithm.
- When a mismatch occurs, what is the most we can shift the pattern so as to avoid redundant comparisons?
- Answer: the largest prefix of P[0..j] that is a suffix of P[1..j]
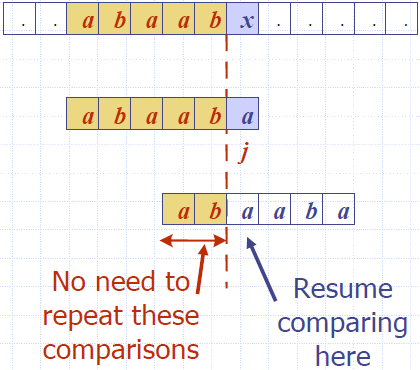
Example